Debunking 6 common pgvector myths
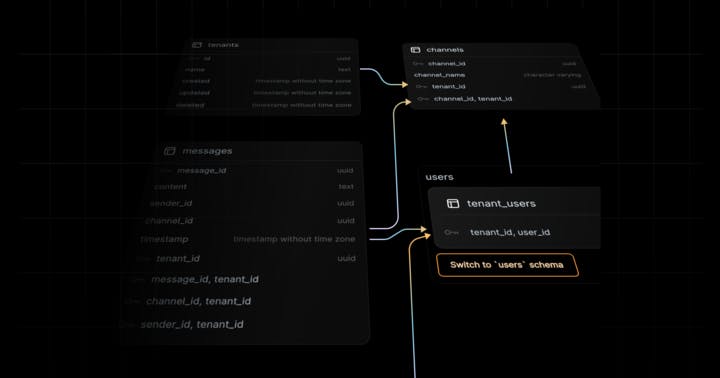
This blog post debunks six common myths surrounding pg_vector, a popular Postgres extension for storing and querying vectors, which is often misunderstood. It clarifies that while vector indexes can enhance performance, they are not always necessary, and different types of vector indexes serve distinct purposes. The post also addresses misconceptions about the limitations on vector dimensions, the evolving nature of pg_vector, and its compatibility with sparse vectors like BM25. Through practical examples, the post highlights how pg_vector offers flexibility in vector storage and retrieval, making it a powerful tool beyond just RAG applications.