Introducing Nile, Serverless Postgres for modern SaaS
I am thrilled to announce Nile, a serverless Postgres database designed for modern SaaS applications. Modern SaaS applications are multi-tenant. We’re the first database that virtualizes tenants into the database. This enables seamless tenant isolation, per-tenant backups, and placement on multi-tenant or dedicated infrastructure, anywhere on the planet. You can do all this with the experience of a single Postgres! You don’t have to manage multiple databases, build complex permissions for isolation, or write buggy scripts to read specific tenant data from backups. On top of the tenant model, we provide opt-in user management capabilities, customer-specific vector embeddings, and instant tenant admin dashboards. You can do all of this with very little code. Moreover, Nile's Postgres is built for the cloud, enabling effortless scaling and a true serverless experience. You can sign up for our waitlist today to try it out.
Before Nile, I spent six years at Confluent, helping transform the company from primarily on-premise to a successful global SaaS company. Through this journey, I learned the challenges of launching and scaling a SaaS product to thousands of customers and tens of thousands of users. We spent significant time managing and isolating tenants, supporting different tenant deployment models, dealing with long downtimes to restore tenant data from backups, and optimizing per-tenant performance. We also had to build the organization and user management capabilities, store and move data to different parts of the company, track usage, bill individual customers, and handle many other SaaS problems. When we spoke to many other companies from different verticals, the problems were similar. All these problems in building SaaS were around data, but the database had little to offer.
We started thinking about what an ideal database for SaaS will look like. What foundational elements would it require? How can we create a fully integrated solution that simplifies the development and scaling of SaaS while also offering the flexibility for developers to integrate with their preferred tools? We picked Postgres as our foundational database. We built tenant virtualization into it, allowing many virtual tenant databases to be placed on physical Postgres databases. We built a single database experience to interact with all these virtual tenant DBs. This was a powerful primitive that provided world-class developer experience and helped solve all the tenant management problems. These virtual tenant DBs are isolated, have their own backups, can be placed on multi-tenant or dedicated infrastructure, and can be deployed to any location worldwide.
On top of this basic foundation of tenants, we also built the concept of users and their relationship with the tenants. The authentication and authorization semantics execute on top of this, providing an impregnable level of security for tenants and users. Storing and querying vector embeddings per tenant becomes trivial. They can now be placed closer to the tenant and scale indefinitely when the index size becomes large and resource-consuming. Finally, the database gives out-of-the-box customer admin dashboards to understand and debug issues with tenant and user growth, insights into per-tenant performance, and management controls to perform administrative operations on tenants and users. Finally, the database is built to be serverless and leverage cloud-native solutions. This database, built from first principles, significantly simplifies the development and scaling of SaaS.
We will go deeper to understand what SaaS is, what it means to say they are modern, the current challenges in building them, and finally, what choices and tradeoffs we made in building the database for modern SaaS.
What makes SaaS modern, and why is it hard to build?
SaaS is a pretty overloaded term at this point, and it would be useful to specify how we define it. We define SaaS as any application that’s multi-tenant. A tenant can be a company, an organization, or a workspace in your product that contains a group of users. Here are a few examples of SaaS products and how tenants and users map to them:
- GitHub helps a group of developers manage and deploy their code. Each Github organization is a tenant, and the developers within those organizations are users.
- Salesforce or Hubspot helps sales reps manage their leads. Each company is a tenant, and the users are the sales reps.
- Ring is a home security company that provides alarm services to different households. Each household is a tenant, and people living in a house using their service are users.
- Toast is a platform to help build software for restaurants. The restaurants are tenants, and the employees of the restaurants are the users.
It is clear from these examples that SaaS is a delivery mechanism and will be leveraged by every vertical, including technology, hardware, manufacturing, industrial, legal, etc. Our insight is that 95% of companies fall into this category, and there’s a massive opportunity to simplify the life of developers building these products.
We've spent years building and talking to SaaS companies identifying the core principles of modern SaaS. They're tenant-centric, secure, globally deployed and scalable, fast and responsive, and provide AI-native experiences. Secondary values like data-centricity, real-time, collaboration and offline mode, and monetization are increasingly important. Let's examine them in more detail based on our experience.
Customer or tenant-centric
A SaaS application provides services to multiple tenants or organizations. Users can create new organizations and get invited to existing ones. They can access the organization irrespective of where they are in the world. One organization's data is perfectly isolated from the other. In addition, you want the performance of one tenant not to affect the other tenants.
There are many other considerations:
- Where is the tenant’s data located?
- What happens when a tenant's data is deleted?
- How long will you keep data backups for each tenant?
- How can you restore a specific tenant’s data?
- How many tenants can you support?
- What are the compliance needs for each customer, etc?
Everything about tenant management is hard. You typically start with a single database and place all the tenants on it. You tackle data isolation between tenants by implementing brittle permission logic at the application level or complex, hard-to-debug, row-level security policies in databases like Postgres. You turn on daily backups but have little idea how to restore data for specific tenants when customers lose data. You end up writing some hacky scripts that are slow and buggy to parse through the backups and extract the tenant data. Once the application has users, you run into your first performance issue. Some tenants are pushing more load, and others have large datasets causing queries to take more resources. This impacts other customers as well. You need help determining which customer is causing the impact and which ones are being impacted. To solve this, you migrate some tenants to dedicated databases, which requires building metadata and sharding logic at the application layer to manage all this. Schema changes, rollouts, monitoring, and developer experience become more complex. This was our story and every other SaaS company's story.
Secure at every step
Modern SaaS is all about being secure by default. The data that belongs to one tenant cannot be exposed to another tenant under any circumstances. This is commonly referred to as tenant data isolation. Users should only be able to see the data of tenants to whom they have access. Most applications need to provide modern authentication support, such as social logins and enterprise logins. There has to be support for a fine-grained permission model for users within a tenant. The same user can have different permission policies across different tenants.
These security needs seem simple but are complex to get right for a multi-tenant application in practice. Most authentication solutions focus on only users and leave developers to think about tenants and the interaction between users and tenants. Organization management is an entire suite of problems that needs deep coordination with the tenant's data in the database. One other critical decision that needs to be made is where the user data resides. Ideally, the primary database should be the source of truth for user data. If not, you must figure out how to sync the data between a third-party service and your primary database. This is a hard problem in distributed systems. Synchronizing user data from a third-party service requires a reliable way to copy it to the primary database, even when failures happen. This cannot be accomplished by stateless event services like webhooks, where you can lose data. You need a reliable replayable event stream to synchronize it. Even with that, you have to deal with eventual consistency in your application. Another option is a two-phase commit between the database and the external service, which is impractical. The cleanest approach is to build auth on top of your source of truth database.
Globally available
All SaaS companies want to be global from day one. At the same time, customers expect great performance and want their compliance needs to be satisfied.
Providing low latency globally is hard because you need more than optimizing the database performance alone. The last mile of receiving the response from the server to the client constitutes a significant part of the latency. For example, the network latency between Sydney, Australia, and New York, USA, is around 200 ms on average. This is probably 10x more than the server-side latency of the database. The only solution is to place the data closer to the tenant.
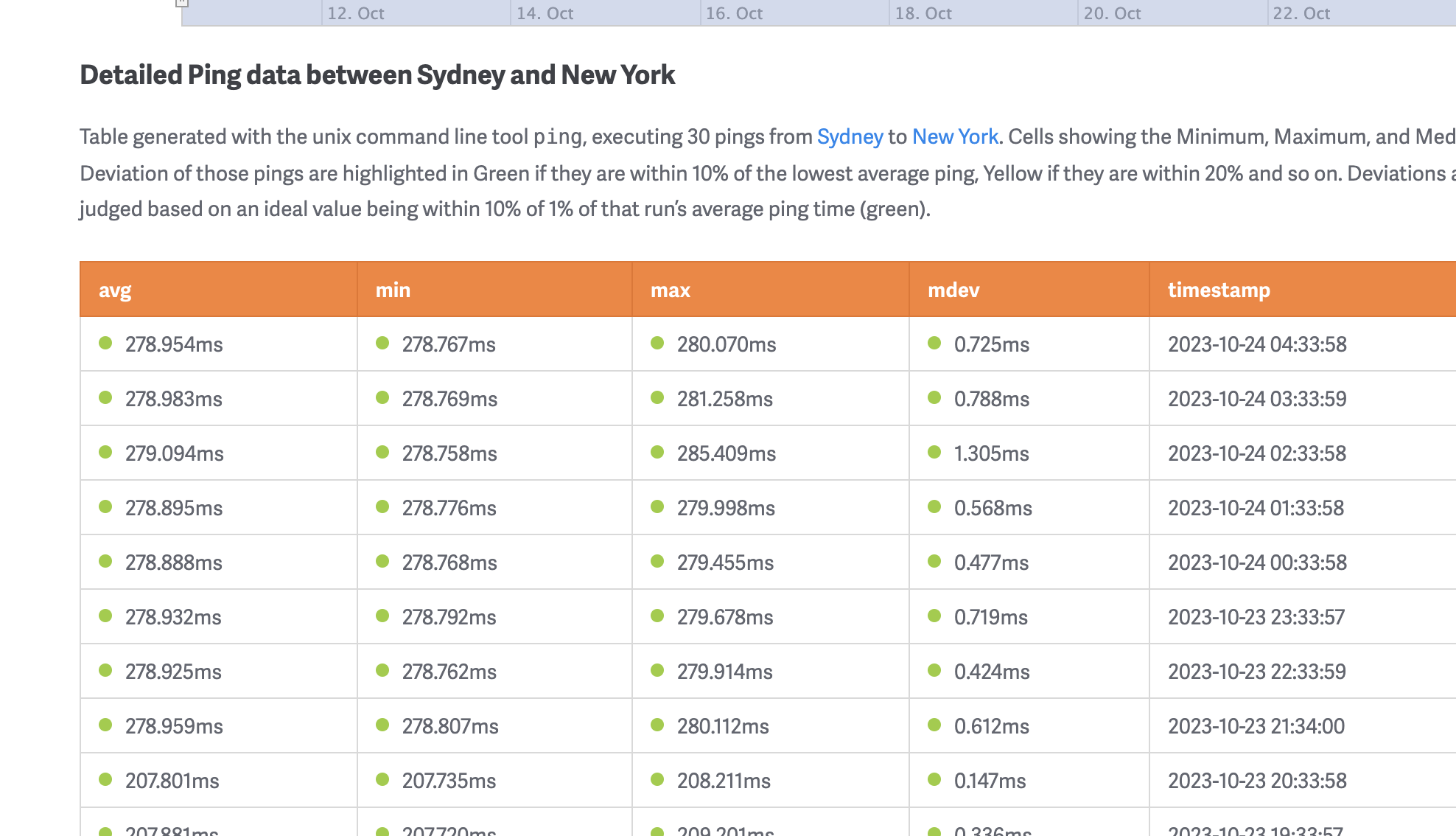 Achieving compliance requirements in different countries is equally hard, and it also needs data to be stored locally in the country where the application is accessed. This, again, requires managing multiple databases distributed across the globe. Most companies lose critical business because they cannot provide this capability.
Achieving compliance requirements in different countries is equally hard, and it also needs data to be stored locally in the country where the application is accessed. This, again, requires managing multiple databases distributed across the globe. Most companies lose critical business because they cannot provide this capability.
Creating and managing multiple databases across different parts of the globe poses many challenges. This is hard as it creates challenges with schema migrations, is expensive to operate, and requires complex sharding and client-side routing. Developers should be abstracted from these problems and spend their time on the core business logic.
AI-native experience
With the rise of GPT and other open-source large language models, AI-native applications have gained massive traction. Instead of AI being a separate vertical, AI will become more immersive in interacting with SaaS applications. For example, GitHub Copilot provides a seamless experience for developers to use as a coding assistant. Notion provides an AI assistant that helps to write documents, rephrase existing writeups, and summarize long articles (like this one). Hubspot provides a personal chatbot for salespeople to have conversations about their leads and pipelines. It is obvious from these examples where this is heading. New product designs will have AI built in from the start.
The difficulty of building the AI infrastructure for SaaS is that you cannot use the large language models directly. They are trained on public data and will typically provide incorrect results. They need tenant-specific data to give relevant results. In addition, there are compliance and security issues with sharing all the private data of tenants to a large language model. This requires building architectures like RAG (more about this later) that require creating tenant-specific vector embeddings, storing them, and augmenting the LLM prompt with the tenant context. This will help with avoiding the hallucination problem and also keep the data secure. The latency of querying these embeddings is another challenge, and network latency from the user to the database will further exacerbate it. Finally, vector indexes like HNSW take significant resources and need horizontal scaling if the embeddings grow fast.
Highly available and scalable
Everyone wants their application to be highly available. SaaS applications used to have weekend maintenance schedules to upgrade the database. Some applications still do! This is no longer acceptable for most users. The expectation is to have 99.99 percentile availability. Also, as the application scales, users want things to work as they used to. They don’t want any interruption in service or any performance degradation.
Building a fully automated technology to manage tenant health proactively is not trivial. You have a service impact if you cannot do zero downtime upgrades. Similarly, you would have customer impact when it takes too long to restore specific tenant data from backups, or developers are manually trying to add more capacity due to a sudden spike in workload or lack of isolation.
In addition to these five principles, modern SaaS also has a few other considerations that are quickly becoming standard.
Data-centric
SaaS applications can be enhanced by providing valuable data insights to the users through the application. Building these data-centric experiences is still a challenge for front-end engineers.
Real-time
This falls into two categories: pushing data as they happen to the application and executing complex business workflows as events happen. Building these flows and connecting all these systems require multiple moving parts today.
Collaborative and offline mode
Applications like Figma and Notion have a collaborative experience built into the product. In addition, you can work offline and sync your data later if you don’t have an internet connection. Techniques like CRDTs needed to solve this are not easy to use.
Monetizable
There is a big shift towards usage-based billing from just charging for the number of seats, especially in these market conditions. The complexity of collecting usage and billing on it is not easy.
Designing a database from first principles for modern SaaS
We had a few key criteria that we wanted to take into consideration when we designed the database. We had to pick a good relational database that was highly performant, and extensible with growing popularity. We wanted to consider supporting multiple tenants and how the experience can still be like a single database. The ability to place tenants anywhere on the planet while not losing any of the benefits of a single database in one location was critical. On top of the tenant model, we wanted to design a foundational user model to help support all the user management capabilities. We also had to think about how we will enable vector embedding per tenant and how to support scaling them. Finally, the ability to scale instantaneously and reduce the cost of storage was key factors.
Postgres
We needed to pick a database we would build our tooling around, and the obvious choice was Postgres. Postgres is a world-class database that is winning in the OLTP space. This trend will continue, and making Postgres easy for building SaaS is the best way for us to have the maximum impact. In my opinion, one of the biggest reasons for Postgres's success is its wide suite of features and extension flexibility. This is a great foundation to build the right tooling around it, making it world-class for SaaS. A solution with Postgres should provide a fully integrated experience while preserving the complete flexibility and extensibility of Postgres. It should also work well with Postgres’s vast tooling ecosystem.
Built-in tenant virtualization
The most foundational element in SaaS is a tenant. It makes a lot of sense to build this core concept into the database. Imagine having a lot of virtual tenant databases that can be co-located on one physical Postgres (multi-tenant) for better cost, and some of them can be placed on a dedicated database for better isolation. The virtual tenant DBs can be located anywhere on the planet for low latency or compliance. The client can route to the right tenant seamlessly without routing logic in the application.
Isolating tenants into their own virtual DBs is great, but you will also want to be able to share data across tenants where it makes sense. Backups should be available for each tenant, and it should be possible to restore them instantaneously. Schema changes should be applied seamlessly across all the tenant DBs, and it should also be possible to do staged rollouts for different tenant tiers. While supporting all this, all the standard SQL capabilities should work across the tenants for admin operations. All the standard Postgres tooling should work. You want the experience of a single Postgres! This sounds like magic, and we can make this magic a reality.
The experience would be something as follows:
Creating a new virtual tenant DB is as simple as a standard insert into the tenant's table. By default, the tenant will get created on a multi-tenant Postgres in the default region. You should be able to specify any location in the world or the infrastructure type if you want a dedicated Postgres for a tenant (more on this in the next section).
-- create a record for the first customer
insert into tenants (name) VALUES ('customer1');
Creating a new table for each tenant should be like standard table creation, and the database should ensure all the virtual tenant DBs get the schema changes applied to them. Let us call them tenant-aware tables.
-- creating an employee table that is tenant aware
create table employees (
tenant_id uuid,
id integer,
name text,
age integer,
address text,
start_date timestamp,
title text,
CONSTRAINT FK_tenants FOREIGN KEY(tenant_id) REFERENCES tenants(id),
CONSTRAINT PK_employee PRIMARY KEY(tenant_id,id));
With the table in place, you can add rows for a specific tenant. Let us say tenant “customer 1” has a few employees that must be added to the system.
-- adding employees for customer 1
insert into employees (tenant_id, id, name, age, address, start_date, title)
values
('018ac98e-b37a-731b-b03a-6617e8fd5266',1345,'Jason',30,'Sunnyvale,California','2016-12-22 19:10:25-07','software engineer'),
('018ac98e-b37a-731b-b03a-6617e8fd5266',2423,'Minnie',24,'Seattle,Washingtom','2018-11-11 12:09:22-06','sales engineer'),
('018ac98e-b37a-731b-b03a-6617e8fd5266',4532,'Shiva',32,'Fremont, California','2019-09-05 04:03:12-05','product manager');
Now, let us assume a second tenant, “customer 2” needs to be added to the system, and a few employees are added to this new tenant. This would again create another virtual tenant DB. The inserts will route to the right virtual tenant DB, but the experience will be like simply inserting into the employee's table.
-- create the second customer
insert into tenants (name) VALUES ('customer2');
-- insert employees for the second customer
insert into employees (tenant_id, id, name, age, address, start_date, title)
values
('018aca35-b8c4-7674-882c-30ae56d7b479',5643,'John',36,'London,UK','2017-12-12 19:10:25-07','senior software engineer'),
('018aca35-b8c4-7674-882c-30ae56d7b479',1532,'Mark',27,'Manchester,UK','2022-10-10 12:09:22-06','support engineer'),
('018aca35-b8c4-7674-882c-30ae56d7b479',8645,'Sam',42,'Liverpool,UK','2015-08-04 04:03:12-05','product manager');
Directing queries to a specific tenant DB and getting full data isolation should be as easy as specifying the tenant ID in the session context . The client library can even abstract this by invoking this for you, depending on what tenant_id is trying to access data. This should all work out of the box without struggling with complex permissions, managing multiple databases, or dealing with error-prone row-level security policies.
-- set the session context to a specific tenant
-- who needs to be isolated.
set nile.tenant_id = '018ac98e-b37a-731b-b03a-6617e8fd5266';
select * from employees
| tenant_id | id | name | age | address | start_date | title |
|---|---|---|---|---|---|---|
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 1345 | Jason | 30 | Sunnyvale,California | 2016-12-22 19:10:25 | software engineer |
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 2423 | Minnie | 24 | Seattle,Washington | 2018-11-11 12:09:22 | sales engineer |
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 4532 | Shiva | 32 | Fremont, California | 2019-09-05 04:03:12 | product manager |
The best part is you should still be able to query across the tenant DBs like a standard table if you don’t specify any context.
select * from employees
| tenant_id | id | name | age | address | start_date | title |
|---|---|---|---|---|---|---|
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 1345 | Jason | 30 | Sunnyvale,California | 2016-12-22 19:10:25 | software engineer |
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 2423 | Minnie | 24 | Seattle,Washington | 2018-11-11 12:09:22 | sales engineer |
| 018ac98e-b37a-731b-b03a-6617e8fd5266 | 4532 | Shiva | 32 | Fremont, California | 2019-09-05 04:03:12 | product manager |
| 018aca35-b8c4-7674-882c-30ae56d7b479 | 5643 | John | 36 | London,UK | 2017-12-12 19:10:25 | senior software engineer |
| 018aca35-b8c4-7674-882c-30ae56d7b479 | 1532 | Mark | 27 | Manchester,UK | 2022-10-10 12:09:22 | support engineer |
| 018aca35-b8c4-7674-882c-30ae56d7b479 | 8645 | Sam | 42 | Liverpool,UK | 2015-08-04 04:03:12 | product manager |
While there’s a need for virtual tenant DBs that isolate data, there’s also a need to share data across tenants. It should be easy to create shared tables that can be accessed by/[across] all tenants and are globally available. All standard queries should work seamlessly both on tenant-aware and shared tables
-- list of flights that a corporate travel booking site can use to share across all the tenants.
-- employees in different tenants can view these flight data to book tickets
create table flights (
id integer PRIMARY KEY,
name text,
from_location text,
to_location text,
departure_time TIMESTAMP,
arrival_time TIMESTAMP
);
Global and flexible tenant placement
When building a modern SaaS application, the critical factors that need to be considered are latency, performance isolation, compliance, and cost. The capability of a database to place tenants has a significant impact on achieving this balance.
Placement can be of two types:
Regional placement
You want to place individual tenants (customers) in different regions worldwide for compliance or latency reasons. You should be able to create the tenant database in any available location without worrying about the number of databases or the operational complexity.
insert into tenants (name, region)
values ('customer 1', 'aws-us-east1');
insert into tenants (name, region)
values ('customer 2', 'aws-eu-west1');
Infrastructure placement
You will want to place tenants in a multi-tenant or dedicated physical database. The decision for this will depend on the customer's needs, cost, and level of isolation needed. Typically, you would start to place all your customers in a multi-tenant database and then have the need to place some tenants on dedicated physical databases.
insert into tenants (name, region, deployment_mode)
values ('customer 2', 'aws-us-east1', 'dedicated');
The client should be able to route to the right tenant without any work from the user. Also, while providing all the placement flexibility, the magic lies in providing the ability to manage all these tenants in different locations and placements like a single Postgres instance. Here are a couple of examples where this will be useful:
Make schema changes once, and the database should apply the change across all the virtual tenant DBs
-- the bookings table where each row represents a single booking
-- for a specific employee within a customer/tenant
create table bookings (
tenant_id uuid,
booking_id integer,
employee_id text,
flight_id integer,
total_price float,
PRIMARY KEY(tenant_id,booking_id));
Query across tenants for insights like a single database
-- Calculates the total no of candidates per tenant that have
-- applied for a job for a recruiting product. Can be used to define
-- active tenants
select t1.id as customer_id,t1.name as customer_name,
count(c1.id) as no_of_candidates from candidates c1
right join tenants t1 on c1.tenant_id=t1.id group by t1.id,t1.name;
First-class support for users
The first basic primitive of a database built for SaaS is tenants. The second is users. Managing users in the context of tenants is complex, and having built-in support will make application development significantly faster. In addition, it will help to store user data in the database with strong consistency and correctness. Authentication should provide a suite of tools that makes it easy to drop in a form to get end-to-end authentication supported for tenants and users in minutes. This should support the entire lifecycle of tenant or organization management, including inviting users to an organization, deleting an organization that soft deletes the tenants in the underlying database, and providing overrides for each tenant to configure custom authentications.
For permissions, basic enforcement of what data users get access to should be easier than it is today. When a user belongs to a specific tenant, access should automatically be restricted to other tenants. You don’t need application logic or complex SQL policies to enforce and maintain this. In addition, permissions should have a flexible language to help define fine-grained column-level resource permissions. The best part is that no instrumentations are required in code, which is often buggy due to the different paths that need to be secured. Instead, permission at source is the strongest security guarantee you can get.
While the database should provide a fantastic solution out of the box, it should also be flexible for users to bring their own auth. This includes building your own authentication or integrating another third-party auth with the database. Great developer platforms can provide flexibility and let developers have finer control over how they want to build out their applications.
Domain and tenant-aware AI-native architecture
Every SaaS application will be an AI-native application like every software application was a SaaS-native application when SaaS happened. SaaS revolutionized how software was delivered. AI will revolutionize how software is experienced.
AI for SaaS needs to be specific to the domain and tenant. For example,
- A corporate wiki (e.g., Confluence, Notion) where the employees can perform a semantic search on their company data
- A chatbot for a CRM (e.g., Salesforce, Hubspot) that sales reps can use to ask questions about past and future customer deals and can have a back-and-forth conversation
- An autopilot for developers in their code repository (Github, Gitlab) to improve productivity. The autopilot should run on the company's code as well, apart from learning from public repositories.
A powerful architecture to achieve this is Retrieval augmented generation(RAG). The idea is to prevent large language models from hallucinating by augmenting the prompt with relevant context. This is usually done by converting the tenant's data set and the query to a common format called embeddings. The prompt issued by the user belonging to a specific tenant will be augmented with more context from that tenant's embeddings. This helps LLMs to be more contextual and also more secure.
A database for SaaS should have native support for storing vector embeddings per tenant. It should also help store the metadata relevant to each tenant and the embeddings. Given Postgres is our choice, the pgvector extension combined with tenant virtualization would be powerful.
create table wiki_documents(tenant_id uuid, id integer, embedding vector(3));
insert into wiki_documents(tenant_id, id, embedding)
values ('018ade1a-7843-7e60-9686-714bab650998', 1, '[1,2,3]');
select embedding <-> '[3,1,2]' as distance from wiki_documents;
You get the following benefits with such a system:
- Embeddings and metadata computed and stored per tenant
- Embeddings and metadata are stored near the customer to speed up the first-byte response to a query
- HNSW and IVFLAT index support from pg_vector
- Unlimited scaling of embeddings since tenants can be distributed and sharded. HNSW is a pretty resource-intensive
- Purpose-built SDKs that integrate with LLM hosts such as OpenAI and Huggingface and vector embeddings.
Serverless and cloud-native
Serverless is how developers will adopt databases in the next decade. Before anyone jumps to say, “There is no such thing as serverless. There are only other people's servers”, the intent of using serverless is to define the experience developers get. It does not mean that the database is implemented without any servers! A database for SaaS should allow developers to focus on their queries, use cases, and core application logic. Developers don’t have to worry about managing capacity, the server configurations, or paying for capacity they don’t use. This gets even more complex if you want to manage multiple databases for each tenant. A database should let you have any number of virtual tenant databases but give you all the goodness of serverless. It should enforce price limits and ensure developers don’t get a sticker shock. The goal of serverless is to care about developers, which is exactly what it should do.
The second thing is that the database needs to be built for the cloud. This means leveraging the native cloud infrastructure to build a highly scalable and elastic system. It makes sense to decouple storage and compute and push storage to cloud storage like S3. This helps to keep the compute stateless and makes it easier to scale them quickly. You still want to shard the tenants across databases and regions to provide placement flexibility (regional and infrastructure placement) and scale the storage as needed.
Tenant-level insights and administration
A huge part of building and running a SaaS application is to understand the growth and performance of each tenant and optimize it. This has been traditionally hard for SaaS. Most want a simple way to look up their active customers, users, and product usage to understand better how the different queries are performing for each customer.
The database should have native support for this. Given it understands tenant boundaries, users within those tenants, and all the queries executed in that context, it would be trivial to show relevant insights to the developers. Developers should be able to understand the growth of the product, how the query performs for each tenant, and past trends. All the performance metrics, usage metrics, and even logs can be understood for each tenant. Postgres tools such as pg_stats, EXPLAIN, and ANALYZE should work and provide insights by tenant.
World-class developer experience
Databases still need to be made easier to use. While Postgres does a great job, there is still a lot of friction in the end-to-end developer journey to build SaaS applications with a cloud-native database. Developers should be able to test locally with the DB for a rapid feedback loop on their laptop, create test databases to apply schema changes, and then migrate to production. This whole experience should be integrated well with a change management system like GitHub. Lastly, ensuring a thriving developer community around the database is key to helping each other and learning quickly.
And some more
There are many more things I chose not to talk about now. Things like propagating real-time changes per tenant to the front end, supporting analytics to build data-centric applications, and leveraging usage data per tenant for monetization are all critical topics in building SaaS. The tenant virtualization is the basic building block. Many SaaS tooling and integrations can be built on this foundation to make it easy to build and scale the product. We would love to hear your feedback and thoughts about this on our GitHub discussion forum or Discord community.
Nile - a company to accelerate modern SaaS
Nile is a company that was started to make the database that I explained a reality. The mission of Nile is to enable developers to accelerate the next billion modern SaaS applications. What we will build at Nile will help accomplish this and truly change the future of SaaS. Nile will deliver on this promise. If you are building SaaS, we would love to talk to you. If you are an amazing engineer, we would love to have you join us in this mission.
You can try out Nile by signing up for our waitlist today. We are onboarding new users every day. You can get started with one of our quickstarts. We also have templates and demos that will make it easy to get started. We would love to have you try out Nile, give us feedback, and help us build something truly world-class. If you need help, you can reach us on our GitHub discussion forum or our Discord community. Follow us on Twitter or Linkedin to get regular updates.
We are building something truly wonderful and are excited about this journey!